LLM-Based RAG Evaluation Metrics: Model Relatedness and Consistency
Evaluating the Evaluators: How LLM Relatedness Impacts Scoring-Based Metrics in RAG Systems
6 August 2025
We recently conducted a study to assess the reliability of large language models (LLMs) when used as evaluators in scoring-based metrics—particularly Faithfulness, a core component in the evaluation of retrieval-augmented generation (RAG) systems.
As LLM-generated outputs become increasingly used in finance and other high-stakes domains, many organizations rely on other LLMs to evaluate those outputs. For example, a generation model might produce a response to a query, and a separate evaluator model is tasked with scoring that response—often based on how well it adheres to a source document. This has become a common pattern in modern RAG pipelines. But how trustworthy are the models doing the judging? In particular, how does relatedness of generator and evaluator models impact scoring artificially?
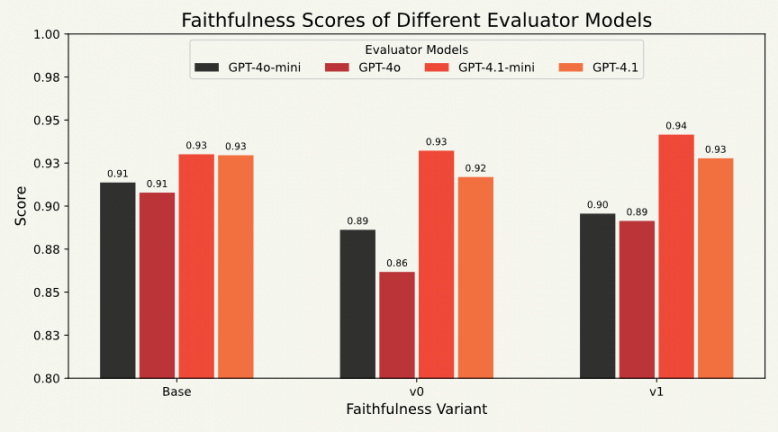
Our research suggests the answer is more complex than it might seem. We compared a range of evaluator models, of varying degrees of relatedness to generator model, scoring the same set of generated outputs obtained using STAC-AI™ LANG6 (Inference-Only) benchmark. In doing so, we found that while generator and evaluator relatedness may artificially inflate scoring bias, the inter-generational (e.g., GPT-4.1 vs GPT-4o) and intra-generational (e.g., GPT-4.1 vs GPT-4.1-mini) differences in evaluators' comprehension abilities better explain score variability.
We also uncovered important differences in score stability. Some models produced consistent evaluations across multiple runs. Others did not. In the latter case, score variation wasn’t simply due to ambiguity in the task—it reflected a deeper issue: a failure to grasp the structure of the evaluation rubric. This finding calls into question the reliability of scoring-based metrics, especially when used to guide system optimization during model development.
To address this, we introduce a simple but useful distinction: some variation in scores is tolerable, arising from the natural ambiguity in human language tasks. Other variation is non-tolerable, resulting from evaluator confusion or miscomprehension.
Based on our findings, we recommend that teams developing LLM-based evaluation metrics utilize a family of LLM models, to better uncover comprehension bias of evaluator models. Optimizing for scoring stability can also increase confidence in the reliability of the scores. More importantly, attention should be paid not just to reducing all variation, but to identifying and minimizing the non-tolerable kind—the variation that signals a breakdown in evaluator understanding.
These findings offer timely guidance for organizations building and refining RAG systems, especially as more of the evaluation process is delegated to foundation models.
STAC subscribers can access the full research note here. Subscribers can also use the STAC-AI Test Harness to benchmark evaluators in their own environments. To learn more about subscription options, please contact us.
About STAC News
For the latest on research, events and related news please see stacresearch.com/news
This page is where you will find archived articles.